もっち
大手SIerに18年勤務。オンプレ・クラウド計200台規模の大規模インフラ(10システム)を統括する現役のサービスマネージャーです。
システム運用・インフラ技術、マインドセット、キャリア戦略など、現場で役立つ情報を若手エンジニアへ向けて発信中。
もっち
大手SIerに18年勤務。オンプレ・クラウド計200台規模の大規模インフラ(10システム)を統括する現役のサービスマネージャーです。
システム運用・インフラ技術、マインドセット、キャリア戦略など、現場で役立つ情報を若手エンジニアへ向けて発信中。
インフラエンジニアの仕事において、最も技術力と精神力が試されるのが「原因不明の障害」です。ログを見ても、監視データを見ても、明確な答えが見つからない。そんな「詰み」の状態をどう突破するか。
18年の現場経験から辿り着いた、論理的かつ戦略的な「障害対応のフレームワーク」を、実体験をもとに解説します。
この記事の想定読者
この記事を読むことでのメリット
アラートが鳴り響いた瞬間、エンジニアが真っ先にすべきことは、キーボードを叩くことでも、ログを漁ることでもありません。
まず、「今、誰に、どんな影響が出ているか」を1分以内に把握します。サービスが継続できているのか、全停止しているのか。この判定がその後の優先順位をすべて決めます。
影響範囲を確認したら、あえてコーヒーを一口飲みます。 これは冗談ではなく、リーダーとして「凪(なぎ)」の状態を作るための重要な儀式です。パニック状態での判断は、しばしば被害を拡大させます。一拍置くことで、脳を「反射」から「思考」のモードへと切り替えます。
以前、仮想サーバ上のWindows OSが突如再起動を繰り返す事象に遭遇しました。イベントログには「予期せぬシャットダウン」の記録のみ。OSベンダーに調査を依頼しても「原因不明」という回答。
このような時、多くの現場では「OSの不具合」として片付けられがちですが、真実を見極めるには「レイヤー構造」に沿った冷徹な切り分けが必要です。
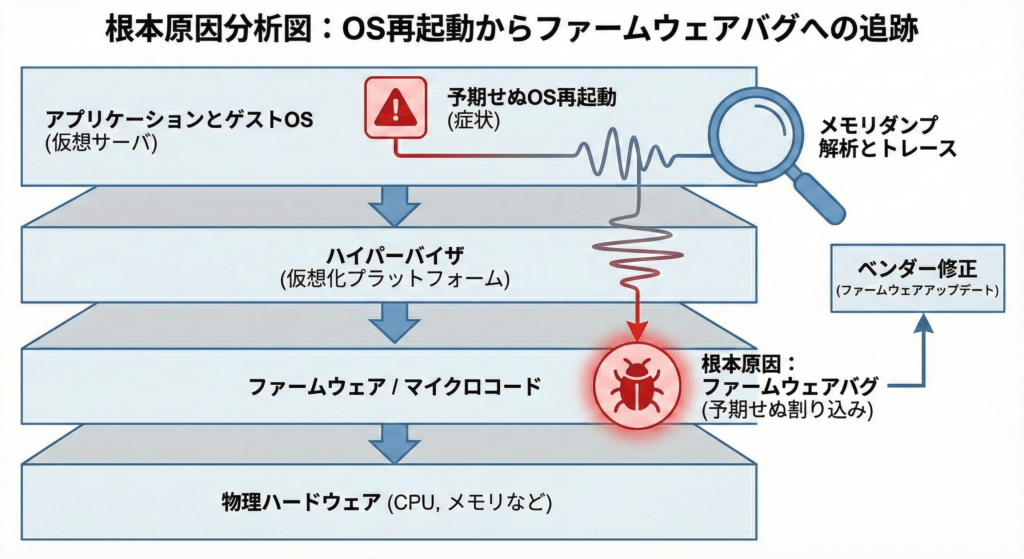
私は、OSベンダーと協力し、メモリダンプ(障害発生時のメモリの内容を記録したもの)の徹底的な解析を行いました。
当初は不具合を否定していたハードウェアベンダーに対し、この「処理の足跡」をエビデンスとして突きつけることで、最終的にファームウェアのバグを認めさせ、修正リリースの発行まで漕ぎ着けることができました。
障害対応中、チームを崩壊させないための秘訣は、「やることを明確に分担させること」です。
| 役割 | 目的 |
| 解析担当 | ログやダンプを深掘りし、技術的な原因を追究する |
| 監視担当 | 現状の稼働状況やリソース推移を常にモニタリングする |
| 報告担当 | 顧客や社内への進捗報告、エスカレーションを専任する |
「全員で画面を覗き込む」のは最悪の手です。リーダーは、メンバーを適切なポジションに配置し、一人ひとりが「今、自分は何をすべきか」に迷わない状態を維持しなければなりません。
「原因がわかってから報告しよう」――この考え方は、インフラエンジニアの信頼を損なう最大の要因です。
顧客が最も恐れているのは、障害そのものではなく「状況が見えないこと」です。
障害対応は、終わった後の「振り返り」で初めて完結します。
障害対応は、エンジニアを最も成長させてくれる「最高の教材」です。冷静な判断と、エビデンスに基づく執念、そしてスピード感のある報告。これらを磨き続けることが、信頼されるインフラエンジニアへの道だと信じています。
「アラートは成長の招待状」です。この招待状を手に、運用監視オペレーターから脱出して市場価値の高いエンジニアを目指しませんか?次に進むべき具体的なステップを段階別に解説しています。

本記事では、18年の経験から得た「障害対応のロジック」について解説しました。しかし、実際の現場では、論理だけでは語り尽くせない「人間の葛藤」や「リーダーとしての孤独」がありました。
深夜のデータセンターで、焦るメンバーを前に私が何を思い、なぜあえて「コーヒーを飲む」という選択をしたのか。
技術解説のサイドストーリーとして、一人のエンジニアの内面的な記録をNoteに綴りました。ロジックの裏側にある「泥臭い人間模様」に興味がある方は、ぜひあわせて読んでみてください。
▼Noteで読む:リーダーとしての葛藤と覚悟の物語 深夜のアラートと、一杯のコーヒー。リーダーの私が「背中で語る」と決めた夜