もっち
大手SIerに18年勤務。オンプレ・クラウド計200台規模の大規模インフラ(10システム)を統括する現役のサービスマネージャーです。
システム運用・インフラ技術、マインドセット、キャリア戦略など、現場で役立つ情報を若手エンジニアへ向けて発信中。

もっち
大手SIerに18年勤務。オンプレ・クラウド計200台規模の大規模インフラ(10システム)を統括する現役のサービスマネージャーです。
システム運用・インフラ技術、マインドセット、キャリア戦略など、現場で役立つ情報を若手エンジニアへ向けて発信中。
インフラエンジニアにとって、基盤のアップデートは避けて通れない一大イベントです。特に「24時間365日、絶対に止められないサービス」を預かっている場合、そのプレッシャーは相当なものです。
先日、私が担当する8台のESXi環境で実施したアップデート作業。そこには、技術的な手順以上に重要だった「緻密なリソース計算」と「泥臭い社内・外の調整」がありました。現場のリアルな記録と、次回に活かすためのチェックリストを共有します。
この記事の想定読者
この記事を読むことでのメリット
この記事で扱う「VMware(ヴィエムウェア)」は、現代のITインフラを支える最も重要な技術の一つです。まずは、初めての方に向けて簡単に概要を説明します。
今回の記事は、この「引っ越し」を駆使しながら、止めてはいけない本番システムをどう守り抜いたか、という現場の記録です。
今回のアップデート計画を立てるにあたり、前提となる構成とサービス要件は以下の通りでした。
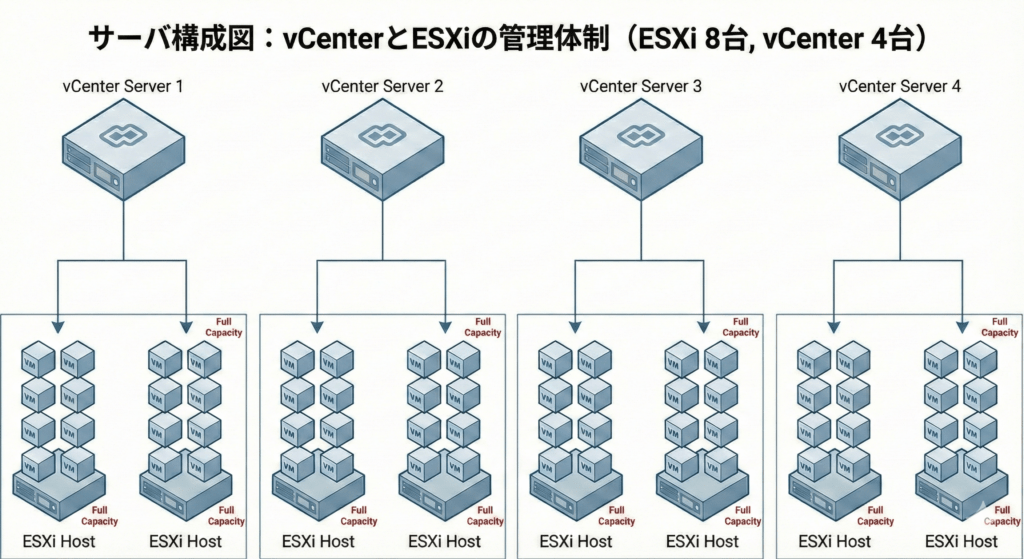
この「逃げ場のない構成」と「止まらないサービス」の組み合わせが、今回のパズルの難易度を極限まで高めていました。1台をメンテナンスモードにするためには、ペアとなるもう一方のホストへ全ての負荷を安全に集約させ、かつサービスへの瞬断すら許されないという緊張感の中での作業となります。
「深夜作業が当たり前」と思われがちなインフラ保守ですが、今回はあえて「平日の日中帯」を主戦場に選びました。その根拠は、1週間にわたるリソース推移の徹底的な確認です。
1週間単位の推移を確認したところ、夜間はバックアップやバッチ処理で負荷が高く、逆に日中帯の方が相対的に負荷が低いことが判明しました。曜日別では、火曜日と水曜日が「凪(なぎ)」の状態。この客観的なデータが、日中作業という決断を後押ししました。
vMotionでVMを片寄せする際、最大の壁はメモリです。計算の結果、以下の通り、余裕ありセットと、余裕なしのセットがありました。
余裕ありのセットはvMotionで片方のESXiサーバ上で稼働する仮想サーバを空にすることで、メンテナンス可能です。
一方、余裕なしのセットはメモリが足りず、vMotionで仮想サーバを片寄せすることができません。そこで、業務に影響を与えない待機系サーバ、管理系サーバを停止することを考えました。それでもメモリが足りない部分は、トレーニング環境を停止させることで、最小限の影響としました。
| 対応グループ | 現状の判断 | 具体的なアクション |
| 余裕あり(2セット) | 片寄せ可能 | そのままvMotionで片方のESXiを空にする |
| 余裕なし(2セット) | 片寄せ不可 | 待機系(Standby)サーバを一時停止 管理系サーバを一時停止 トレーニングサーバを一時停止(顧客調整済み) |
作業当日、最も大切なのは「何時までに終わらなければ、作業を諦めて引き返すか」という切り戻し基準の顧客との合意です。
| 時間帯 | 通常スケジュール | 切り戻し(リカバリ)発生時 |
| 10:00 – 12:00 | 退避作業 (vMotion・一部停止) | – |
| 12:00 – 14:30 | アップデート作業 | – |
| 14:30 – 16:30 | 戻し作業・動作確認 | – |
| 16:30 | 完了判断 | 切り戻し開始のデッドライン |
| 17:00 – 21:00 | (完了・安定稼働モニタリング) | 切り戻し作業(ダウングレード等) |
| 21:00 – 23:00 | – | 環境復旧・動作確認 |
| 23:00 – 翌朝 | – | 最終バッファ時間(翌朝まで確保) |
作業自体はスケジュール通り完了しましたが、1点だけ「調整不足」によるヒヤリハットがありました。
トレーニングサーバを停止した際、顧客内での周知は完璧でしたが、「自社の別システム運用チーム」への周知が漏れていました。その結果、連携する別システム側でエラー検知が発生し、他チームのエンジニアに突発的な調査作業を強いてしまったのです。
今回の経験を、次回の自分と、同じ悩みを持つエンジニアのためにチェックリスト化しました。
24/365のサービスを支えるインフラ屋にとって、「何事もなかった1日」こそが最高の報酬です。
今回のアップデートが成功したのは、最新の技術を駆使したからではなく、2ヶ月前からの泥臭い調整と、石橋を叩き壊すようなリソース計算があったからです。この記事が、あなたの現場の「平穏な1日」に繋がれば幸いです。
緻密な計画と調整を経てアップデートを完遂したら、最後はマネージャーへの報告です。現場の苦労と成果を正しく評価につなげるための『通る報告書』の書き方も併せて確認しておきましょう。