もっち
大手SIerに18年勤務。オンプレ・クラウド計200台規模の大規模インフラ(10システム)を統括する現役のサービスマネージャーです。
システム運用・インフラ技術、マインドセット、キャリア戦略など、現場で役立つ情報を若手エンジニアへ向けて発信中。

もっち
大手SIerに18年勤務。オンプレ・クラウド計200台規模の大規模インフラ(10システム)を統括する現役のサービスマネージャーです。
システム運用・インフラ技術、マインドセット、キャリア戦略など、現場で役立つ情報を若手エンジニアへ向けて発信中。
インフラエンジニアとして現場に立ち、現在はサービスマネージャーとして約200台のサーバーと10の基幹システムを預かる立場から断言できるのは、「システムの挙動はプロセスの挙動そのものである」ということです。
サーバーのレスポンス低下、リソースの枯渇、予期せぬサービス停止。これらのトラブルに直面した際、OSが裏側でどのようにプロセスを管理しているのかという「原理原則」を知っているかどうかで、復旧までのスピードと判断の正確さが決まります。
本稿では、OSの心臓部である「プロセス管理」について、実務に耐えうるレベルまで詳細に解説します。
この記事の想定読者
この記事を読むことでのメリット
コンピュータサイエンスにおいて、プログラムとプロセスは明確に区別されます。
OSは膨大な数のプロセスを管理するために、プロセス制御ブロック(PCB: Process Control Block)というデータ構造をカーネルメモリ内に保持します。
PCBには、プロセスID(PID)、プログラムカウンタ、CPUレジスタの内容、メモリ割り当て情報、入出力状態などが記録されます。OSはこのPCBを読み書きすることで、複数のプロセスを切り替えながら並行処理を実現しています。
サービスマネージャーが監視ツールで「CPU使用率」や「ロードアベレージ」を見る際、その裏側ではプロセスが激しく状態を変えています。プロセスの状態遷移を理解することは、ボトルネックの正体を見破ることに直結します。
プロセスは生成から終了まで、主に以下の5つの状態を遷移します。
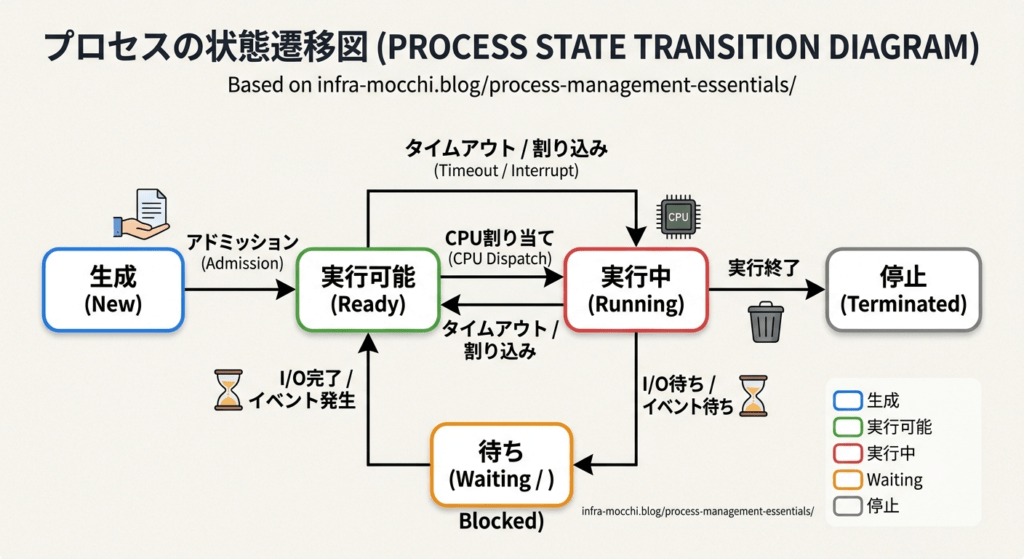
サービスマネージャーの視点では、「Waiting状態のプロセスが滞留していないか」が重要です。これはCPUの問題ではなく、ストレージやネットワークのI/Oボトルネックを示唆しているからです。
大規模システムにおいて、限られたCPUコアを数千のプロセスで分け合う技術が「マルチタスク」です。
CPUがあるプロセスから別のプロセスへと処理を切り替える際、現在実行中のプロセスのレジスタ情報をPCBに保存し、次のプロセスのPCBを読み込む処理が発生します。
これをコンテキストスイッチと呼びます。 この切り替え自体はOSのオーバーヘッドであり、有用な処理は行われません。そのため、プロセスの切り替え頻度が高すぎると、システム全体のパフォーマンスが著しく低下(スラッシング)します。
OSがCPUリソースをどのプロセスに割り当てるかを決定する「スケジューリング」は、システムのパフォーマンスを左右する要です。主要なアルゴリズムの特性を下表にまとめました。
| アルゴリズム名 | 概要 | メリット | デメリット・課題 |
| 先着順 (FIFO) | 到着した順にプロセスを実行する。 | 実装が単純で、管理のオーバーヘッドが最小。 | 実行時間の長いジョブが先に来ると後続が待たされる(コンボイ現象)。 |
| ラウンドロビン (RR) | 一定時間(タイムクォンタム)ごとに実行権を切り替える。 | 公平性が高く、応答性が良いため対話型システムに適す。 | 切り替え頻度が高いとコンテキストスイッチの負荷が増大する。 |
| 最短ジョブ優先 (SJF) | 実行予定時間が最も短いものを優先する。 | 平均待ち時間を理論上、最小化できる。 | 実行時間の予測が困難。長いジョブが実行されない「飢餓状態」のリスク。 |
| 優先度順 | 各プロセスに優先度を設定し、高いものから実行する。 | 重要な処理を確実に優先できる。 | 低優先度のプロセスがいつまでも実行されない可能性がある。 |
| 多段階フィードバックキュー | 複数のキューを使い、挙動に応じて優先度を動的に変更する。 | I/OバウンドとCPUバウンドのプロセスをバランスよく処理できる。 | アルゴリズムの設計やパラメータ調整が非常に複雑。 |
複数のプロセスが連携して一つのシステムを構成する場合、プロセスをまたいだデータの受け渡し(通信)と、その整合性を保つための「交通整理(同期)」が不可欠です。
プロセスは通常、OSによってメモリ空間が完全に隔離されています(メモリ保護)。そのため、データを共有するにはOSが提供する以下のIPCメカニズムを利用する必要があります。
複数のプロセスが共有メモリなどのリソースに同時にアクセスし、処理の順序によって結果が変わってしまう状態をレースコンディション(競合状態)と呼びます。
例えば、共有の変数に対して「読み取る→1足す→書き込む」という処理を2つのプロセスが同時に行うと、本来2増えるはずが、互いの書き込みを上書きしてしまい1しか増えないという不整合が起こります。これを防ぐために、特定のコード範囲(クリティカルセクション)には同時に一プロセスしか入れないように制限をかけます。
データの整合性を守るための「鍵」や「信号」の役割を果たすのが以下の仕組みです。
同期制御を厳格に行いすぎると、デッドロックという問題が発生します。 「プロセスAがリソース1を確保したままリソース2を待ち、プロセスBがリソース2を確保したままリソース1を待つ」という、互いに身動きが取れなくなる状態です。
インフラ設計やアプリケーション開発においては、ロックを取得する順番を統一するなどの設計ルールを設けることで、このデッドロックを回避することが極めて重要です。
18年のキャリア、そしてサービスマネージャーとしての実務の中で、理論だけでは防げなかったトラブルが多々あります。
Linuxサーバーにおいて、子プロセスが終了した際に親プロセスが適切にその終了を看取らない(waitシステムコールを発行しない)と、プロセスは「終了したはずなのに管理テーブルに残り続ける」状態になります。
これがゾンビプロセスです。 ある時、アプリケーションの不具合でこれが数万件規模で累積しました。メモリやCPUは消費していませんでしたが、OSのPID(プロセスID)の最大値を使い果たしてしまいました。この結果、新しいプロセスを一切生成できなくなり、保守ログインすら不可能な「サービス全停止」という事態を招きました。
8コアのCPUを搭載したサーバーで、特定の1プロセスが無限ループに陥ったケースです。 OSのスケジューラは、そのプロセスを特定の1コアに割り当て続けます。
この時、「サーバー全体のCPU使用率平均」は12.5%程度しか示しません。しかし、その1コアで動いていた基幹サービスはレスポンス不能に陥っていました。 「全体の平均値」だけを監視していると、こうした「コア単位の異常」を見逃し、障害検知が遅れるという痛恨の教訓となりました。
近年の主流であるDockerなどのコンテナ技術は、OSレベルで見れば「強力に隔離された、単なるプロセス」に過ぎません。コンテナを運用するということは、突き詰めればOSのプロセス管理を高度に使いこなすことと同義です。
仮想化、コンテナ、サーバーレスと技術は進化しますが、その根底にあるOSのプロセス管理の仕組みは変わりません。この基礎を深く理解することこそが、大規模システムを預かるサービスマネージャー、そして一流のインフラエンジニアへの最短ルートです。