もっち
大手SIerに18年勤務。オンプレ・クラウド計200台規模の大規模インフラ(10システム)を統括する現役のサービスマネージャーです。
システム運用・インフラ技術、マインドセット、キャリア戦略など、現場で役立つ情報を若手エンジニアへ向けて発信中。
保有資格
ITサービスマネージャー、
ネットワークスペシャリスト
情報処理安全確保支援士
AWS SAP、ITIL Foundation
もっち
大手SIerに18年勤務。オンプレ・クラウド計200台規模の大規模インフラ(10システム)を統括する現役のサービスマネージャーです。
システム運用・インフラ技術、マインドセット、キャリア戦略など、現場で役立つ情報を若手エンジニアへ向けて発信中。
ITサービスマネージャー、
ネットワークスペシャリスト
情報処理安全確保支援士
AWS SAP、ITIL Foundation
このブログでは、読者の立場により記事を4つのスキルフェーズに分けています。それぞれの自分に合ったフェーズの記事を確認してみてください。
▼▼▼まずはここからチェック!

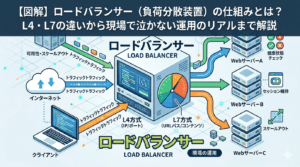
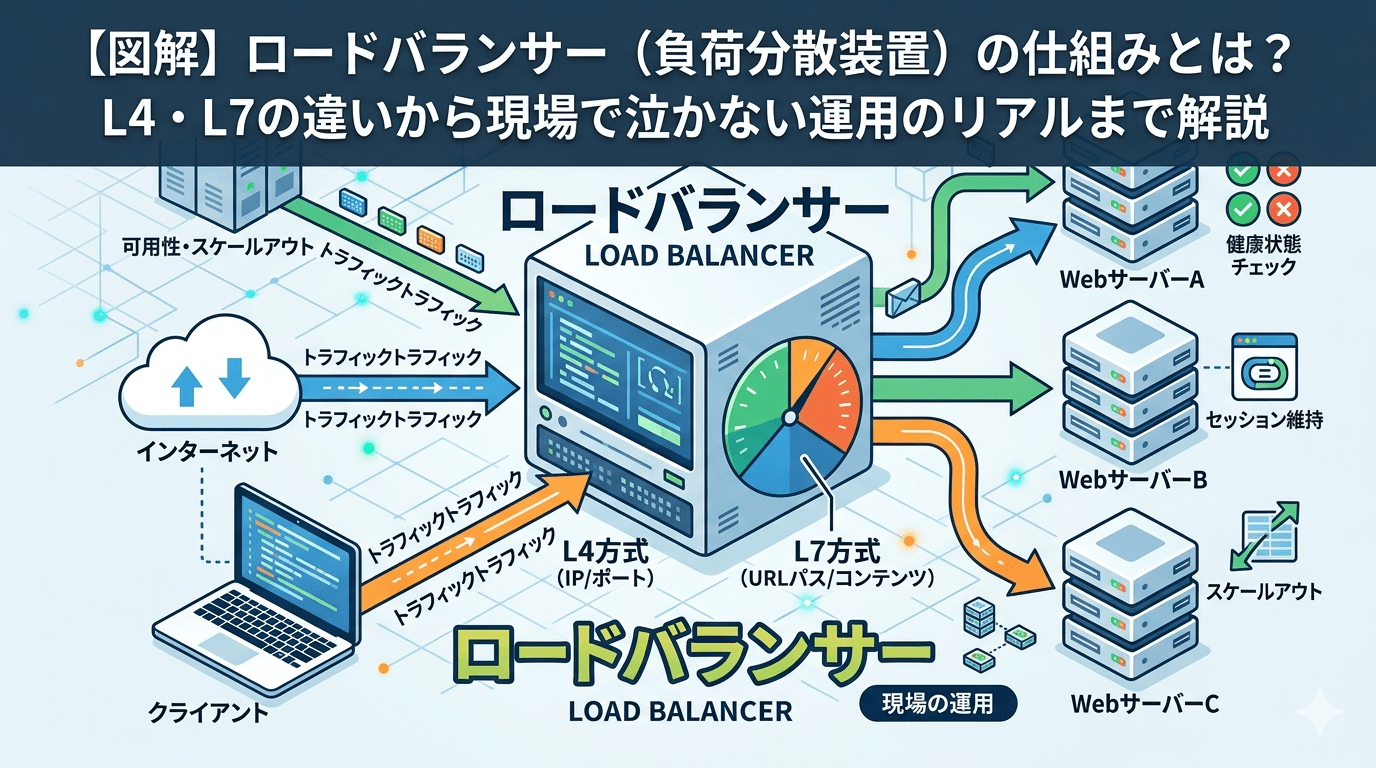
Webシステムのインフラを支える上で、欠かせない存在であるロードバランサー(LB:負荷分散装置)。
「教科書で仕組みは勉強したけれど、実際の現場ではどう運用されているの?」
「障害が起きたとき、LB環境下でどうやって原因を切り分ければいいかわからない……」
そんな疑問や不安を抱えている若手エンジニアの方も多いのではないでしょうか。
実務において、LBは単なる交通整理の機械ではなく、時にインフラエンジニアを最も悩ませる「迷宮」へと変貌します。「本番環境で1台だけアプリが落ちているのに検知できない」「メンテナンス後の動作確認では正常だったのに、一般公開した途端にエラーが多発する」といったトラブルは、現場で本当によく起こる光景です。
本記事では、ロードバランサーの体系的な基礎知識やパケットの詳しい流れをおさらいしつつ、障害対応やメンテナンスで大火傷を負わないための「現場のリアルな知恵」を徹底解説します。
ロードバランサーの最大の目的は、「負荷分散(スケーラビリティ)」と「高可用性(サバイバビリティ)」です。
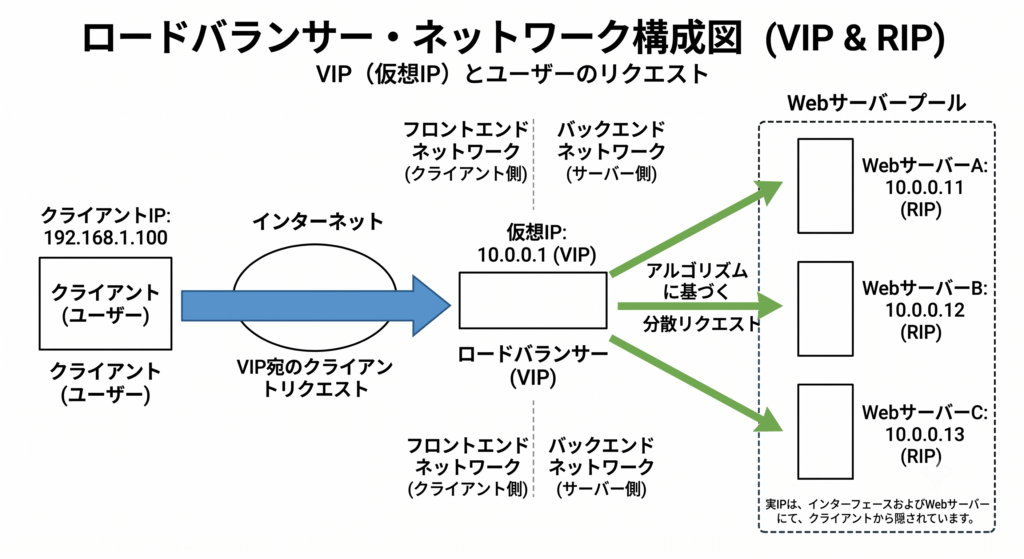
クライアント(ユーザー)からのアクセスを1箇所で受け止め、後ろに控える複数のWebサーバーへ上手に交通整理をします。このとき、ネットワーク的に重要となるのがVIPとRIPという2つのIPアドレスです。
クライアントからはWebサイトが1つの大きなサーバー(VIP)で動いているように見えますが、その裏では複数のRIPを持つサーバーたちが処理を分け合っています。
LBは、OSI参照モデルのどのレイヤーで交通整理をするかによって、大きく2種類に分かれます。システムの要件定義やトラブルシューティングの方向性を決める極めて重要な違いです。
| 項目 | L4ロードバランサー | L7ロードバランサー |
| 動作レイヤー | トランスポート層(第4層) | アプリケーション層(第7層) |
| 判断基準 | IPアドレス、ポート番号 | URLのパス、HTTPヘッダー、Cookieなど |
| 特徴 | 処理がシンプルで非常に高速 | 細かな条件分岐や高度な制御が可能 |
| 代表例 | L4スイッチなど | Nginx(リバースプロキシ)など |
障害調査でパケットキャプチャ(tcpdumpなど)を叩いたとき、多くの若手エンジニアが「あれ?クライアントのIPが見当たらない」「どことどこが通信しているのかわからない」と混乱します。
なぜなら、ロードバランサー(L7リバースプロキシやFull NATなど)を経由する際、パケットに書き込まれている「送信元IP(Src)」と「宛先IP(Dst)」が途中で目まぐるしく書き換わるからです。
具体的な数値を例に、パケットの往復の流れを完全に可視化してみましょう。
192.168.1.100(Client-IP)10.0.0.1(外部向けの受付窓口)10.0.0.2(サーバーと通信する実体IP)10.0.0.11(実際に処理する裏方のサーバー)ユーザーがブラウザでWebサイトにアクセスした瞬間です。パケットはLBの「受付窓口(VIP)」を目指して飛んでいきます。
192.168.1.100(クライアント)10.0.0.1(LBのVIP)パケットを受け取ったLBは、振り分けアルゴリズムに従って「今回はWebサーバーAに処理を任せよう」と決めます。そして、パケットの送信元と宛先をどちらも書き換えてサーバーAに転送します。
10.0.0.2(LBの内部IPに変身!)10.0.0.11(WebサーバーAのRIPに変身!)💡 ここが実務のポイント!
WebサーバーAの視点に立つと、パケットの送信元(Src)はクライアントのIPではなく、**「LBの内部IP(
10.0.0.2)」**に見えています。そのため、Webサーバー側のアクセスログをそのまま見ると、すべてのアクセスがLBから来ているように見えてしまい、本当のクライアントIPが分かりません。(※これを防ぐため、LBはHTTPヘッダーに
X-Forwarded-For: 192.168.1.100のように元のクライアントIPを仕込んでサーバーに渡すのが一般的です)。
WebサーバーAが処理を終え、画面のデータを返します。サーバーAから見ると、頼んできた相手は「LB(10.0.0.2)」なので、LBに向けてパケットを返却します。
10.0.0.11(WebサーバーA)10.0.0.2(LBの内部IP)サーバーからデータを受け取ったLBは、「これはさっき192.168.1.100のクライアントから頼まれた分だな」と判断し、最後にパケットの仮面を元に戻してクライアントへ返します。
10.0.0.1(LBのVIPに戻る!)10.0.0.100(クライアントのIPに戻る!)一連の変化をタイムラインで表にまとめると、以下のようになります。
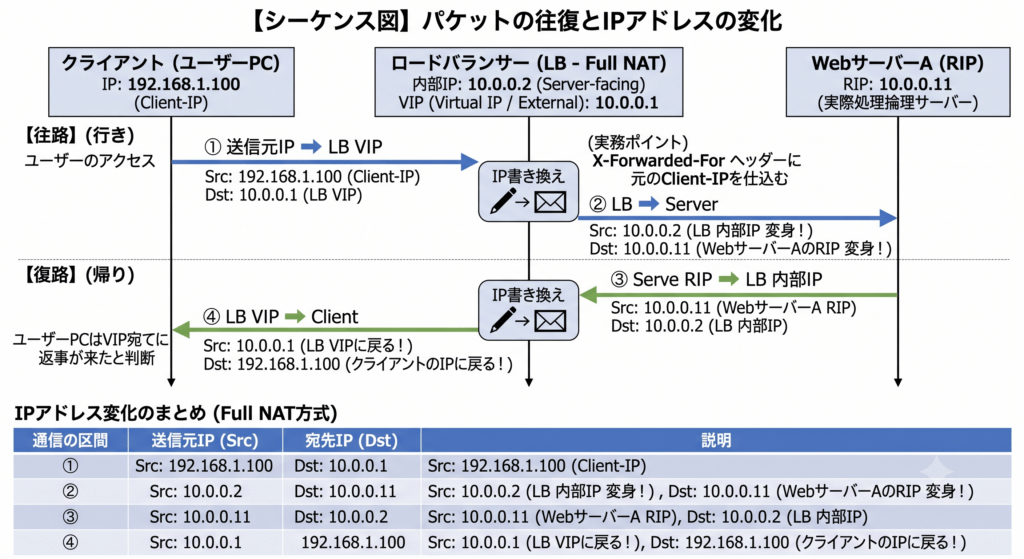
| 通信の区間 | 送信元IP (Source) | 宛先IP (Destination) | 説明 |
| ① クライアント→LB | 192.168.1.100 | 10.0.0.1 (VIP) | クライアントがVIP宛てに送信 |
| ② LB→Webサーバー | 10.0.0.2 (LB内部) | 10.0.0.11 (RIP) | LBが両方のIPを書き換えて転送 |
| ③ Webサーバー→LB | 10.0.0.11 (RIP) | 10.0.0.2 (LB内部) | サーバーがLB宛てに返信 |
| ④ LB→クライアント | 10.0.0.1 (VIP) | 192.168.1.100 | LBが元の仮面に戻してクライアントへ |
後述する「障害調査の難しさ」の理由はここにあります。通信が分散されるだけでなく、IPアドレス自体がLBの前後で「ガワ」を変えられてしまうため、このパラメータ変化を完璧に頭に入れておかなければ、パケットの迷宮に迷い込むことになります。
LBがどのように接続先を決めるのか、その「ルール」にあたるのが振り分けアルゴリズムです。そして、そのルールを補完するのがセッション維持(パーシスタンス)の仕組みです。
ECサイトでの買い物カゴや、ログイン状態の維持など、Webアプリケーションの多くは「一連の行動(セッション)」を特定のサーバーが覚え続ける必要があります。ラウンドロビンで毎回違うサーバーに飛ばされてしまうと、画面を遷移するたびにログアウトされてしまうといった問題が発生します。
これを防ぐために、CookieやソースIPアドレスを使って、一度紐付いたサーバーへ固定する仕組みが「セッション維持(スティッキーセッション)」です。
仕組み自体はシンプルに見えますが、実務においてはここが大きな落とし穴になります。
LBは、裏側のWebサーバーが正常に動いているかを常に監視し、壊れたサーバーがあれば自動的に切り離す機能を持っています。
主に L3(Ping)、L4(TCP)、L7(HTTP/HTTPS)のレベルで行われますが、ここで非常に重いトラブルとなるのが、「ヘルスチェックは通っているのに、アプリケーションは死んでいる」という状態です。
例えば、ヘルスチェックの対象をトップページ(index.html)といった静的ファイルにしていると、裏側でデータベース(DB)との接続が切れてエラー画面が出ている状態でも、LBは「Webサーバー自体は応答しているから正常!」と判断します。結果、エラーを吐き続けるサーバーにお客さんを誘導し続けてしまうのです。
ヘルスチェックを行う際は、内部の健全性を判定できる専用のパス(例:/health_check)を用意するのが鉄則です。
「ソースIP保持」によるセッション維持を選択している場合、社内プロキシや特定のゲートウェイを経由した大量のアクセスが、すべて同一のWebサーバー1台に偏ってしまう(負荷が集中する)という現象が起きることがあります。設計時には、ユーザーのアクセス経路の特性を考慮しなければなりません。
ここからが、実務で最もインフラエンジニアの頭を悩ませる「現場のリアル」です。
「一部のユーザーからだけ、たまにエラーが出ると問い合わせがあるが、社内でテストしても再現しない」
こうしたランダムに見える不具合の多くは、複数あるWebサーバーのうちの1台だけでバグや局所的なリソース枯渇が発生しているケースです。LBが通信を分散しているため、運悪くその不具合サーバーに当たった通信だけがエラーになります。
また、深夜のアプリケーションアップデートなどのメンテナンス後、LBのVIP宛てにブラウザからアクセスして「よし、画面が表示された!メンテ完了!」と判断するのは極めて危険です。その確認通信は「正常にアップデートできたA機」に届いただけで、隣の「起動に失敗して火を噴いているB機」には届いていなかったかもしれないからです。
この罠を回避するために、現場のインフラエンジニアは決してLBだけを信じて確認作業を終えません。
実務では、LBを経由させずに、検証端末のhostsファイルを書き換えるなどして、各WebサーバーのIPアドレス(RIP)を直接指定し、1台ずつ個別にアクセスして動作確認を行います。
このように、通信の経路を完全にコントロールして1台ずつ「直撃」させることで、初めて確実なリリースや正確な障害切り分けが可能になります。
ロードバランサーが絡むシステムで障害が起きたとき、あるいはメンテナンスを行うときは、以下の言葉を常に念頭に置いてください。
「パケットの流れがLBによって分散・変換されるため、LBを経由する通信の確認には細心の注意を払うべきである」
そして、トラブルが起きてから慌てないために、日頃から以下の3つの「仕様」を確認しておく癖をつけましょう。
これらが頭に入っていれば、障害時に「まずどこを切り離し、どこのパケットを追えばいいか」の戦術が瞬時に組み立てられるようになります。仕組みを学ぶだけでなく、その仕組みが実務でどう牙を剥くのか。そこまでを想定できて初めて、インフラの安定稼働を支えるプロフェッショナルと言えるのです。
このブログでは、読者の立場により記事を4つのスキルフェーズに分けています。それぞれの自分に合ったフェーズの記事を確認してみてください。
▼▼▼まずはここからチェック!